
對抗假新聞的另類做法:以評分系統標示優質新聞/Frederic Filloux
發展一套內容網站和作者的品質評分系統,除了能夠有效挖掘出網路上的優質內容之外,也是對抗假新聞的利器。為了達到這個目標,必須找出足以評斷內容品質的各種「訊號指標」(signals),將這些指標綜合比較才行。


假新聞查核系統的盲點
近來內容網站和大型內容通路平台總算下定決心,開始認真面對假新聞問題。其中多數人的解決方案,都是打算連結各種事實查核平台,像是Politifact、Snopes、FactCheck.org等,以便檢閱網路上多如牛毛的內容是否信而有徵。
法國世界報(Le Monde)推出了一個能夠為網站內容可信度評分的搜尋引擎,叫做「Decodex」。這個搜尋引擎有時候是有用的,但有時候不見得能正確運作。我試著拿一些由Outbrain(譯註:一個惡名昭彰的垃圾內容廣告聯盟。網站安裝其內容推薦外掛後,會在頁面中呈現相關推薦內容;但出現的內容品質多半非常糟糕)推薦的一堆垃圾內容去試,結果Decodex完全不知道這些內容,也無法做出評斷。
持平而論,Decodex系統推出至今還不到兩個月,而且正在快速改善。現在正是法國總統大選前夕,對於假新聞偵測與可信報導的需求呼聲甚高,也是發燒話題。世界報與另外42家法國新聞媒體,也同時加入了由Google操盤的計畫「CrossCheck」(詳見Medium上這篇由Google Labs發布的說明)。
在內容通路平台方面,Facebook最近推出了一個系統,同樣倚靠第三方事實查核組織的資料,以標記所謂「爭議消息」(如下圖所示):
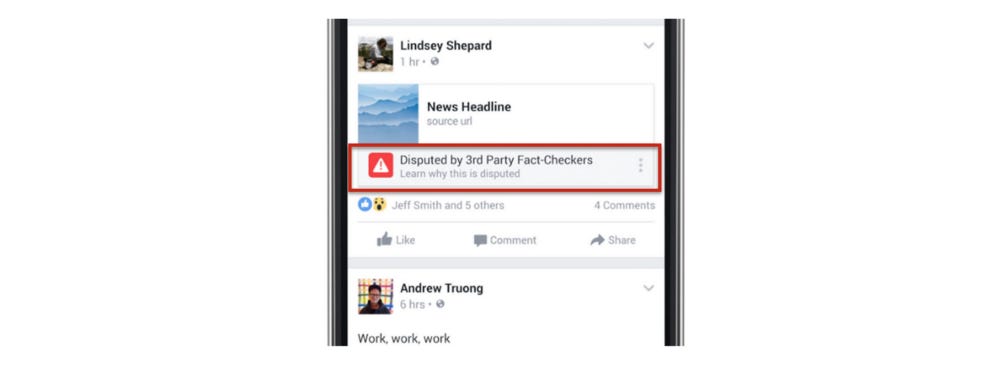
不只Facebook開始與多家內容業者合作,Google也不斷微調修正其搜尋演算法,所以現況仍在不停變化之中。這個周末,我在Google搜尋中輸入「Obama planning」(歐巴馬正在計畫),然後搜尋框自動補上了「a coup」(一場政變),有五十多萬個搜尋結果:

假新聞風暴就像是失控的生物改造瘟疫一般,某些人為了牟利,大規模操弄錯誤資訊,導致這場瘟疫蔓延全球。當專業媒體因而四面受敵時,民主也同時遭到威脅。
以優質新聞評分標示系統,間接對抗假新聞
由於各種急迫的需求,假新聞偵測機制著重在治癒症狀,而非找出病因;假新聞偵測的著眼點不在於更高層次的優質內容,而且還沒辦法大規模部署。這對每天傳遞巨量內容的社群或內容聚合通路平台來說,是很大的問題。要知道,在Facebook上分享的連結,每天多達一億個!
我在史丹佛大學 John S. Knight 學院進行的研究計畫,主要是著重在大規模突顯網路上的優質內容。和直接偵測垃圾內容不同,這個計畫以另一種方式來解決網路內容品質的問題。
請容我以對太陽系之外行星的探索為例說明。目前的太空技術,還無法直接觀測到遙遠的類地行星,所以天文學家改用間接的觀測方法,設法歸納出這些類地行星的存在與其結構。例如他們會注意觀測行星的「凌」現象,也就是當行星通過地球和某一顆恆星時,該恆星的亮度將會微幅下降;天文學家也同時觀測恆星本身與其背景發出的紅外線幅射,以及當重力場發生擾動時的亮度變化,甚至是行星運動時造成恆星質量中心點的微幅偏移,如下圖:
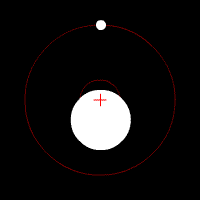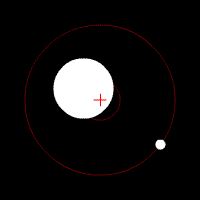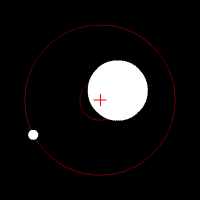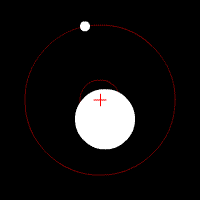
回到新聞產業的討論,仔細檢閱一系列精確設定的「信號指標」,就能挖掘出許多優質內容的不同面向,同時也必然能夠處理假新聞問題;因為這種作法最終是在評估內容網站和作者的信譽。雖然Facebook、Google和各大新聞平台不願公開承認,但其實大家都已經開始使用類似的品質評分系統。
對新聞業來說,建立這樣的品質評分系統,是非常敏感的。新聞媒體是否能夠接受這樣的體系,要看這種體系要如何呈現。畢竟要對上千個內容網站和記者分級,依可信程度將其放到不同的等級,以此建立某種程度的白名單體系,一定會引發爭議。這就像是美國的TSA Pre機場安檢制度一樣。
如何針對內容和網站進行評分
要怎麼實作這樣的制度?以下分成內容網站和作者兩方面來說明。
評價內容網站的方式,可以參照其組織的相對規模、歷史(包括得過哪些新聞獎項、創刊至今的年份),這些資訊就能提供相當的參考價值,如下圖:
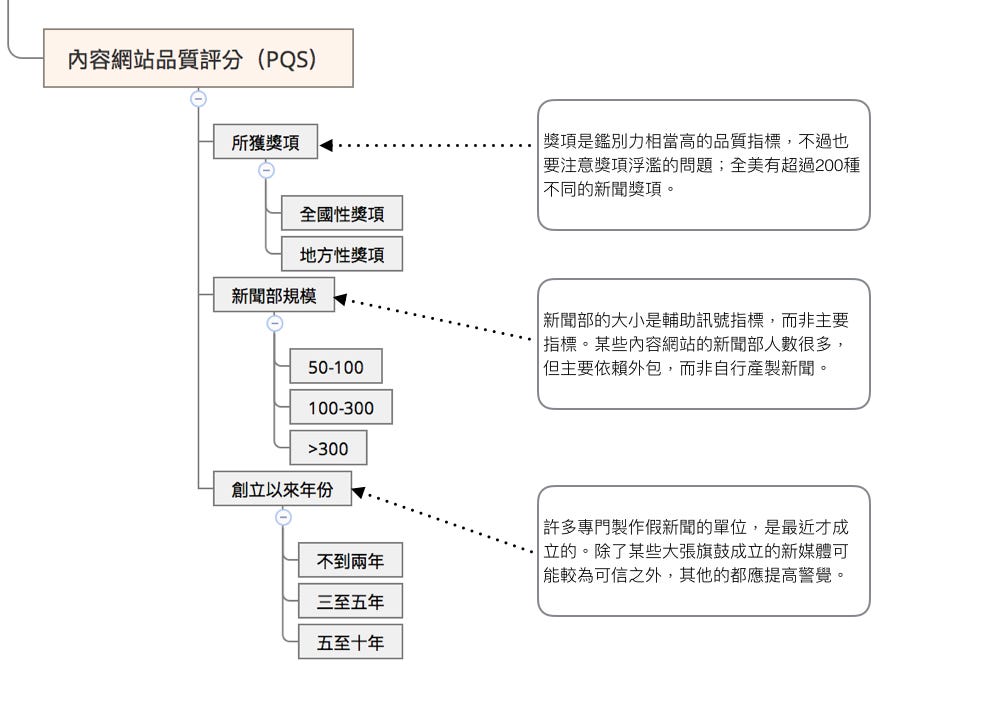
也可以用類似的架構來進行作者評價:

當然,魔鬼一向藏在細節裡。有很多因素必須謹慎以對,例如內容網站是否開放API,讓外部合法取用其內容、判斷錯誤造成的傷害、偽造的個人或組織經歷等等。但這將會是好的開始,十分值得一試。(這兩個月來我分析了來自五百多個美國網站、八百五十個RSS的近一萬篇內容)
另外,這個評分系統還需要其他信號的補充,才能更為完整。像是分析內容網站或作者是否經常是系列報導的來源;如果新聞的生命周期長到能夠形成系列報導,多半表示其品質是較優的。例如每天發稿的地區性新聞,通常具有更高的可預期性,所以得分會比較高。
在新聞內容的部分,也有一些信號會對「內容網站評分」加減分。舉例來說,一篇比較長的文章通常會得到比較正面的評價;但如果其中安插了一些和內容不相關的圖片,或圖片是來自於圖庫的話,其內容的可靠性就有待商榷。
相對的,如果內容網站自行產製圖像內容,也會被視為是自製內容的一部分。其他的內容品質訊號也包括內文的語意結構分析結果、內容的資訊密度,或是有無操弄SEO分數的跡象。
自動收集大量內容加以綜合比對,也能有助於讓系統更加精確地判斷各種訊號的相互之間的重要性。
導入人工智慧深度學習
目前筆者發展的系統中,有四十種不同的主要訊號和次要訊號;即使訊號的種類不多,也需要仔細調整各種訊號的權重。
我在和史丹佛大學校內的資訊科學專家討論,並且展示種種計算過程之後,大家都建議透過人工智慧的深度學習,找出最佳的訊號權重分配比例。我們把一些標示為優質內容的文章餵給神經網路閱讀,讓它學會如何正確評價在語料庫中的大量其他內容。
這種方式十分類似於讓神經網路從一大堆動物照片中找出貓咪的照片,教會神經網路如何分辨貓咪的方法,就是先給它看大量貓咪照片。
目前的問題在於,如果要讓整個系統能夠正確找到優質內容,一定要先餵食上萬篇優質內容給系統判讀。要找到三萬張貓咪照片相對很容易,只要透過群募或直接從既有圖庫中找圖就行了;但即使是餵電腦看僅僅幾千篇優質新聞內容,到目前為止尚未有人試過。所以,前方的路雖然有趣,但仍然十分漫長。